6.21.2. OpenStack reliability testing¶
- status
draft
- version
0
- Abstract
This document describes an abstract methodology for OpenStack cluster high-availability testing and analysis. OpenStack data plane testing at this moment is out of scope but will be described in future. All tests have been performed regarding OpenStack reliability testing
- Conventions
6.21.2.1. Test results¶
6.21.2.1.1. Test environment¶
6.21.2.1.1.1. Software configuration on servers with OpenStack¶
Name |
Build-9.0.0-451 |
OpenStack release |
Mitaka on Ubuntu 14.04 |
Total nodes |
6 nodes |
Controller |
3 nodes |
Compute, Ceph OSD |
3 nodes with KVM hypervisor |
Network |
Neutron with tunneling segmentation |
Storage back ends |
Ceph RBD for volumes (Cinder)
Ceph RadosGW for objects (Swift API)
Ceph RBD for ephemeral volumes (Nova)
Ceph RBD for images (Glance)
|
6.21.2.1.1.2. Software configuration on servers with Rally role¶
Before you start configuring a server with Rally role, verify that Rally is installed. For more information, see Rally installation documentation.
Software |
Version |
|---|---|
Rally |
0.4.0 |
Ubuntu |
14.04.3 LTS |
6.21.2.1.1.2.1. Environment description¶
6.21.2.1.1.3. Hardware¶
SERVER |
name |
728997-comp-disk-228
728998-comp-disk-227
728999-comp-disk-226
729000-comp-disk-225
729001-comp-disk-224
729002-comp-disk-223
|
729017-comp-disk-255 |
role |
controller
controller
controller
compute, ceph-osd
compute, ceph-osd
compute, ceph-osd
|
Rally |
|
vendor, model |
HP, DL380 Gen9 |
HP, DL380 Gen9 |
|
operating_system |
3.13.0-87-generic
Ubuntu-trusty
x86_64
|
3.13.0-87-generic
Ubuntu-trusty
x86_64
|
|
CPU |
vendor, model |
Intel, E5-2680 v3 |
Intel, E5-2680 v3 |
processor_count |
2 |
2 |
|
core_count |
12 |
12 |
|
frequency_MHz |
2500 |
2500 |
|
RAM |
vendor, model |
HP, 752369-081 |
HP, 752369-081 |
amount_MB |
262144 |
262144 |
|
NETWORK |
interface_name |
p1p1 |
p1p1 |
vendor, model |
Intel, X710 Dual Port |
Intel, X710 Dual Port |
|
bandwidth |
10 Gbit |
10 Gbit |
|
STORAGE |
dev_name |
/dev/sda |
/dev/sda |
vendor, model |
raid10 - HP P840
12 disks EH0600JEDHE
|
raid10 - HP P840
12 disks EH0600JEDHE
|
|
SSD/HDD |
HDD |
HDD |
|
size |
3,6 TB |
3,6 TB |
6.21.2.1.1.4. Software¶
Role |
Service name |
|---|---|
controller |
horizon
keystone
nova-api
nava-scheduler
nova-cert
nova-conductor
nova-consoleauth
nova-consoleproxy
cinder-api
cinder-backup
cinder-scheduler
cinder-volume
glance-api
glance-glare
glance-registry
neutron-dhcp-agent
neutron-l3-agent
neutron-metadata-agent
neutron-openvswitch-agent
neutron-server
heat-api
heat-api-cfn
heat-api-cloudwatch
ceph-mon
rados-gw
heat-engine
memcached
rabbitmq_server
mysqld
galera
corosync
pacemaker
haproxy
|
compute-osd |
nova-compute
neutron-l3-agent
neutron-metadata-agent
neutron-openvswitch-agent
ceph-osd
|
6.21.2.1.1.5. High availability cluster architecture¶
Controller nodes:

Compute nodes:

6.21.2.1.1.6. Networking¶
All servers have the similar network configuration:
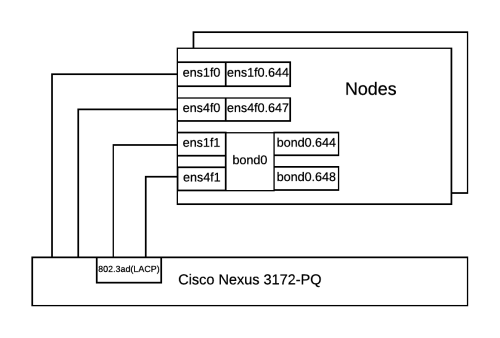
The following example shows a part of a switch configuration for each switch port that is connected to ens1f0 interface of a server:
switchport mode trunk
switchport trunk native vlan 600
switchport trunk allowed vlan 600-602,630-649
spanning-tree port type edge trunk
spanning-tree bpduguard enable
no snmp trap link-status
6.21.2.1.2. Factors description¶
reboot-random-controller: consists of a node-crash fault injection on a random OpenStack controller node.
sigkill-random-rabbitmq: consists of a service-crash fault injection on a random slave RabbitMQ messaging node.
sigkill-random-mysql: consists of a service-crash fault injection on a random MySQL node.
freeze-random-nova-api: consists of a service-hang fault injection to all nova-api process on a random controller node for a 150 seconds period.
freeze-random-memcached: consists of a service-hang fault injection to the memcached service on a random controller node for a 150 seconds period.
freeze-random-keystone: consists of a service-hang fault injection to the keystone (public and admin endpoints) service on a random controller node for a 150 seconds period.
6.21.2.2. Testing process¶
Use the following VM parameters for testing purposes:
Name |
Value |
|---|---|
Flavor to create VM from |
m1.tiny |
Image name to create VM from |
cirros |
Create a work directory on a server with Rally role. In this documentation, we name this directory
WORK_DIR. The path example:/data/rally.Create a directory
pluginsinWORK_DIRand copy thescrappy.pyplugin into that directory.Download the bash framework
scrappy.shandscrappy.conftoWORK_DIR/plugins.Modify the
scrappy.conffile with appropriate values. For example:# SSH credentials SSH_LOGIN="root" SSH_PASS="r00tme" # Controller nodes CONTROLLERS[0]="10.44.0.7" CONTROLLERS[1]="10.44.0.6" CONTROLLERS[2]="10.44.0.5" # Compute nodes COMPUTES[0]="10.44.0.3" COMPUTES[1]="10.44.0.4" COMPUTES[2]="10.44.0.8" #Scrappy base path SCRAPPY_BASE="/root/scrappy"
Create a
scenariosdirectory inWORK_DIRand copy all Rally scenarios with factors that you are planning to test to that directory. For example:random_controller_reboot_factor.json.Create a
deployment.jsonfile in theWORK_DIRand fill it with your OpenStack environment info. It should looks like this:{ "admin": { "password": "password", "tenant_name": "tenant", "username": "user" }, "auth_url": "http://1.2.3.4:5000/v2.0", "region_name": "RegionOne", "type": "ExistingCloud", "endpoint_type": "internal", "admin_port": 35357, "https_insecure": true }
Prepare for tests:
${WORK_DIR:?} DEPLOYMENT_NAME="$(uuidgen)" DEPLOYMENT_CONFIG="${WORK_DIR}/deployment.json" rally deployment create --filename $(DEPLOYMENT_CONFIG) --name $(DEPLOYMENT_NAME)
Create a
/root/scrappydirectory on every node in your OpenStack environment and copyscrappy_host.shto that directory.Perform tests:
PLUGINS_PATH="${WORK_DIR}/plugins" SCENARIOS="random_controller_reboot_factor.json" for scenario in ${SCENARIOS}; do rally --plugin-paths ${PLUGINS_PATH} task start --tag ${scenario} ${WORK_DIR}/scenarios/${scenario} done task_list="$(rally task list --uuids-only)" rally task report --tasks ${task_list} --out=${WORK_DIR}/rally_report.html
Once these steps are done, you get an HTML file with Rally test results.
6.21.2.2.1. Test case 1: NovaServers.boot_and_delete_server¶
Description
This Rally scenario boots and deletes virtual instances with injected fault factors using OpenStack Nova API.
Service-level agreement
Parameter |
Value |
|---|---|
MTTR (sec) |
<=240 |
Failure rate (%) |
<=95 |
Auto-healing |
Yes |
Parameters
Parameter |
Value |
|---|---|
Runner |
constant |
Concurrency |
5 |
Times |
100 |
Injection-iteration |
20 |
Testing-cycles |
5 |
List of reliability metrics
Priority |
Value |
Measurement Units |
Description |
|---|---|---|---|
1 |
SLA |
Boolean |
Service-level agreement result |
2 |
Auto-healing |
Boolean |
Is cluster auto-healed after fault-injection |
3 |
Failure rate |
Percents |
Test iteration failure ratio |
4 |
MTTR (auto) |
Seconds |
Automatic mean time to repair |
5 |
MTTR (manual) |
Seconds |
Manual mean time to repair, if Auto MTTR is Inf. |
6.21.2.2.2. Test case 1 results¶
6.21.2.2.2.1. reboot-random-controller¶
Rally scenario used during factor testing:
{% set flavor_name = flavor_name or "m1.tiny" %}
{% set image_name = image_name or "^(cirros.*uec|TestVM)$" %}
{
"NovaServers.boot_and_delete_server": [
{% for i in range (0, 5, 1) %}
{
"args": {
"flavor": {
"name": "{{flavor_name}}"
},
"image": {
"name": "{{image_name}}"
},
"force_delete": false
},
"runner": {
"type": "constant",
"times": 100,
"concurrency": 5
},
"context": {
"users": {
"tenants": 1,
"users_per_tenant": 1
}
},
"sla": {
"scrappy": {
"on_iter": 20,
"execute": "/bin/bash /data/rally/rally_plugins/scrappy/scrappy.sh random_controller_reboot",
"cycle": {{i}}
}
}
},
{% endfor %}
]
}
Factor testing results:
Cycles |
MTTR(sec) |
Failure rate(%) |
Auto-healing |
Performance degradation |
1 |
4.31 |
2 |
Yes |
Yes, up to 148.52 sec. |
2 |
19.88 |
14 |
Yes |
Yes, up to 150.946 sec. |
3 |
7.31 |
8 |
Yes |
Yes, up to 124.593 sec. |
4 |
95.07 |
9 |
Yes |
Yes, up to 240.893 |
5 |
Inf. |
80.00 |
No |
Inf. |
Rally report: reboot_random_controller.html
Value |
MTTR(sec) |
Failure rate |
Min |
4.31 |
2 |
Max |
95.07 |
80 |
SLA |
Yes |
No |
Detailed results description
This factor affects OpenStack cluster operation on every run. Auto-healing works, but may take a long time. In our testing results, the cluster was recovered on the fifth testing cycle only, after Rally had completed testing with the error status. Therefore, the performance degradation is very significant during cluster recovering.
6.21.2.2.2.2. sigkill-random-rabbitmq¶
Rally scenario used during factor testing:
{% set flavor_name = flavor_name or "m1.tiny" %}
{% set image_name = image_name or "^(cirros.*uec|TestVM)$" %}
{
"NovaServers.boot_and_delete_server": [
{% for i in range (0, 5, 1) %}
{
"args": {
"flavor": {
"name": "{{flavor_name}}"
},
"image": {
"name": "{{image_name}}"
},
"force_delete": false
},
"runner": {
"type": "constant",
"times": 100,
"concurrency": 5
},
"context": {
"users": {
"tenants": 1,
"users_per_tenant": 1
}
},
"sla": {
"scrappy": {
"on_iter": 20,
"execute": "/bin/bash /data/rally/rally_plugins/scrappy/scrappy.sh random_controller_kill_rabbitmq",
"cycle": {{i}}
}
}
},
{% endfor %}
]
}
Factor testing results:
Cycles |
MTTR(sec) |
Failure rate(%) |
Auto-healing |
Performance degradation |
1 |
0 |
0 |
Yes |
Yes, up to 12.266 sec. |
2 |
0 |
0 |
Yes |
Yes, up to 15.775 sec. |
3 |
98.52 |
1 |
Yes |
Yes, up to 145.115 sec. |
4 |
0 |
0 |
Yes |
No |
5 |
0 |
0 |
Yes |
Yes, up to 65.926 sec. |
Rally report: random_controller_kill_rabbitmq.html
Value |
MTTR(sec) |
Failure rate |
Min |
0 |
0 |
Max |
98.52 |
1 |
SLA |
Yes |
Yes |
Detailed results description
This factor may affect OpenStack cluster operation. Auto-healing works fine. Performance degradation is significant during cluster recovering.
6.21.2.2.2.3. sigkill-random-mysql¶
Rally scenario used during factor testing:
{% set flavor_name = flavor_name or "m1.tiny" %}
{% set image_name = image_name or "^(cirros.*uec|TestVM)$" %}
{
"NovaServers.boot_and_delete_server": [
{% for i in range (0, 5, 1) %}
{
"args": {
"flavor": {
"name": "{{flavor_name}}"
},
"image": {
"name": "{{image_name}}"
},
"force_delete": false
},
"runner": {
"type": "constant",
"times": 100,
"concurrency": 5
},
"context": {
"users": {
"tenants": 1,
"users_per_tenant": 1
}
},
"sla": {
"scrappy": {
"on_iter": 20,
"execute": "/bin/bash /data/rally/rally_plugins/scrappy/scrappy.sh send_signal /usr/sbin/mysqld -KILL",
"cycle": {{i}}
}
}
},
{% endfor %}
]
}
Factor testing results:
Cycles |
MTTR(sec) |
Failure rate(%) |
Auto-healing |
Performance degradation |
1 |
2.31 |
0 |
Yes |
Yes, up to 12.928 sec. |
2 |
0 |
0 |
Yes |
Yes, up to 11.156 sec. |
3 |
0 |
1 |
Yes |
Yes, up to 13.592 sec. |
4 |
0 |
0 |
Yes |
Yes, up to 11.864 sec. |
5 |
0 |
0 |
Yes |
Yes, up to 12.715 sec. |
Rally report: random_controller_kill_mysqld.html
Value |
MTTR(sec) |
Failure rate |
Min |
0 |
0 |
Max |
2.31 |
1 |
SLA |
Yes |
Yes |
Detailed results description
This factor may affect OpenStack cluster operation. Auto-healing works fine. Performance degradation is not significant.
6.21.2.2.2.4. freeze-random-nova-api¶
Rally scenario used during factor testing:
{% set flavor_name = flavor_name or "m1.tiny" %}
{% set image_name = image_name or "^(cirros.*uec|TestVM)$" %}
{
"NovaServers.boot_and_delete_server": [
{% for i in range (0, 5, 1) %}
{
"args": {
"flavor": {
"name": "{{flavor_name}}"
},
"image": {
"name": "{{image_name}}"
},
"force_delete": false
},
"runner": {
"type": "constant",
"times": 100,
"concurrency": 15
},
"context": {
"users": {
"tenants": 1,
"users_per_tenant": 1
}
},
"sla": {
"scrappy": {
"on_iter": 20,
"execute": "/bin/bash /data/rally/rally_plugins/scrappy/scrappy.sh random_controller_freeze_process_fixed_interval nova-api 150",
"cycle": {{i}}
},
}
},
{% endfor %}
]
}
Factor testing results:
Cycles |
MTTR(sec) |
Failure rate(%) |
Auto-healing |
Performance degradation |
1 |
0 |
0 |
Yes |
Yes, up to 156.935 sec. |
2 |
0 |
0 |
Yes |
Yes, up to 155.085 sec. |
3 |
0 |
0 |
Yes |
Yes, up to 156.93 sec. |
4 |
0 |
0 |
Yes |
Yes, up to 156.782 sec. |
5 |
150.55 |
1 |
Yes |
Yes, up to 154.741 sec. |
Rally report: random_controller_freeze_nova_api_150_sec.html
Value |
MTTR(sec) |
Failure rate |
Min |
0 |
0 |
Max |
150.55 |
1 |
SLA |
Yes |
Yes |
Detailed results description
This factor affects OpenStack cluster operation. Auto-healing does not work. Cluster operation was recovered only after sending SIGCONT POSIX signal to all freezed nova-api processes. Performance degradation is determined by the factor duration time. This behaviour is not normal for an HA OpenStack configuration and should be investigated.
6.21.2.2.2.5. freeze-random-memcached¶
Rally scenario used during factor testing:
{% set flavor_name = flavor_name or "m1.tiny" %}
{% set image_name = image_name or "^(cirros.*uec|TestVM)$" %}
{
"NovaServers.boot_and_delete_server": [
{% for i in range (0, 5, 1) %}
{
"args": {
"flavor": {
"name": "{{flavor_name}}"
},
"image": {
"name": "{{image_name}}"
},
"force_delete": false
},
"runner": {
"type": "constant",
"times": 100,
"concurrency": 5
},
"context": {
"users": {
"tenants": 1,
"users_per_tenant": 1
}
},
"sla": {
"scrappy": {
"on_iter": 20,
"execute": "/bin/bash /data/rally/rally_plugins/scrappy/scrappy.sh random_controller_freeze_process_fixed_interval memcached 150",
"cycle": {{i}}
},
}
},
{% endfor %}
]
}
Factor testing results:
Cycles |
MTTR(sec) |
Failure rate(%) |
Auto-healing |
Performance degradation |
1 |
0 |
0 |
Yes |
Yes, up to 26.679 sec. |
2 |
0 |
0 |
Yes |
Yes, up to 23.726 sec. |
3 |
0 |
0 |
Yes |
Yes, up to 21.893 sec. |
4 |
0 |
0 |
Yes |
Yes, up to 22.796 sec. |
5 |
0 |
0 |
Yes |
Yes, up to 27.737 sec. |
Rally report: random_controller_freeze_memcached_150_sec.html
Value |
MTTR(sec) |
Failure rate |
Min |
0 |
0 |
Max |
0 |
0 |
SLA |
Yes |
Yes |
Detailed results description
This factor does not affect an OpenStack cluster operations. During the factor testing, a small performance degradation is observed.
6.21.2.2.2.6. freeze-random-keystone¶
Rally scenario used during factor testing:
{% set flavor_name = flavor_name or "m1.tiny" %}
{% set image_name = image_name or "^(cirros.*uec|TestVM)$" %}
{
"NovaServers.boot_and_delete_server": [
{% for i in range (0, 5, 1) %}
{
"args": {
"flavor": {
"name": "{{flavor_name}}"
},
"image": {
"name": "{{image_name}}"
},
"force_delete": false
},
"runner": {
"type": "constant",
"times": 100,
"concurrency": 5
},
"context": {
"users": {
"tenants": 1,
"users_per_tenant": 1
}
},
"sla": {
"scrappy": {
"on_iter": 20,
"execute": "/bin/bash /data/rally/rally_plugins/scrappy/scrappy.sh random_controller_freeze_process_fixed_interval keystone 150",
"cycle": {{i}}
},
}
},
{% endfor %}
]
}
Factor testing results:
Cycles |
MTTR(sec) |
Failure rate(%) |
Auto-healing |
Performance degradation |
1 |
97.19 |
7 |
Yes |
No |
2 |
93.87 |
6 |
Yes |
No |
3 |
92.12 |
8 |
Yes |
No |
4 |
94.51 |
6 |
Yes |
No |
5 |
98.37 |
7 |
Yes |
No |
Rally report: random_controller_freeze_keystone_150_sec.html
Value |
MTTR(sec) |
Failure rate |
Min |
92.12 |
6 |
Max |
98.37 |
8 |
SLA |
Yes |
No |
Detailed results description
This factor affects an OpenStack cluster operations. After the keystone processes freeze on controllers, the HA logic needs approximately 95 seconds to recover service operation. After recovering, performance degradation is not observed but only at small concurrency. This behaviour is not normal for an HA OpenStack configuration and should be investigated in future.
