Filter Scheduler¶
The Filter Scheduler supports filtering and weighting to make informed decisions on where a new instance should be created. This Scheduler supports working with Compute Nodes only.
Filtering¶
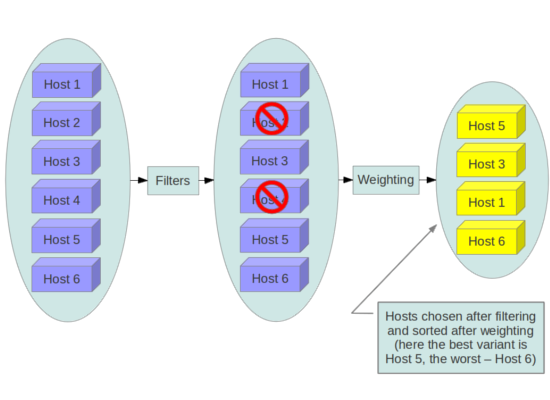
During its work Filter Scheduler iterates over all found compute nodes, evaluating each against a set of filters. The list of resulting hosts is ordered by weighers. The Scheduler then chooses hosts for the requested number of instances, choosing the most weighted hosts. For a specific filter to succeed for a specific host, the filter matches the user request against the state of the host plus some extra magic as defined by each filter (described in more detail below).
If the Scheduler cannot find candidates for the next instance, it means that there are no appropriate hosts where that instance can be scheduled.
The Filter Scheduler has to be quite flexible to support the required variety of filtering and weighting strategies. If this flexibility is insufficient you can implement your own filtering algorithm.
There are many standard filter classes which may be used
(nova.scheduler.filters):
AllHostsFilter- does no filtering. It passes all the available hosts.ImagePropertiesFilter- filters hosts based on properties defined on the instance’s image. It passes hosts that can support the properties specified on the image used by the instance.AvailabilityZoneFilter- filters hosts by availability zone. It passes hosts matching the availability zone specified in the instance properties. Use a comma to specify multiple zones. The filter will then ensure it matches any zone specified.ComputeCapabilitiesFilter- checks that the capabilities provided by the host compute service satisfy any extra specifications associated with the instance type. It passes hosts that can create the specified instance type.If an extra specs key contains a colon (:), anything before the colon is treated as a namespace and anything after the colon is treated as the key to be matched. If a namespace is present and is not
capabilities, the filter ignores the namespace. For examplecapabilities:cpu_info:featuresis a valid scope format. For backward compatibility, when a key doesn’t contain a colon (:), the key’s contents are important. If this key is an attribute of HostState object, likefree_disk_mb, the filter also treats the extra specs key as the key to be matched. If not, the filter will ignore the key.The extra specifications can have an operator at the beginning of the value string of a key/value pair. If there is no operator specified, then a default operator of
s==is used. Valid operators are:* = (equal to or greater than as a number; same as vcpus case) * == (equal to as a number) * != (not equal to as a number) * >= (greater than or equal to as a number) * <= (less than or equal to as a number) * s== (equal to as a string) * s!= (not equal to as a string) * s>= (greater than or equal to as a string) * s> (greater than as a string) * s<= (less than or equal to as a string) * s< (less than as a string) * <in> (substring) * <all-in> (all elements contained in collection) * <or> (find one of these) Examples are: ">= 5", "s== 2.1.0", "<in> gcc", "<all-in> aes mmx", and "<or> fpu <or> gpu"
some of attributes that can be used as useful key and their values contains:
* free_ram_mb (compared with a number, values like ">= 4096") * free_disk_mb (compared with a number, values like ">= 10240") * host (compared with a string, values like: "<in> compute","s== compute_01") * hypervisor_type (compared with a string, values like: "s== QEMU", "s== powervm") * hypervisor_version (compared with a number, values like : ">= 1005003", "== 2000000") * num_instances (compared with a number, values like: "<= 10") * num_io_ops (compared with a number, values like: "<= 5") * vcpus_total (compared with a number, values like: "= 48", ">=24") * vcpus_used (compared with a number, values like: "= 0", "<= 10")
AggregateInstanceExtraSpecsFilter- checks that the aggregate metadata satisfies any extra specifications associated with the instance type (that have no scope or are scoped withaggregate_instance_extra_specs). It passes hosts that can create the specified instance type. The extra specifications can have the same operators asComputeCapabilitiesFilter. To specify multiple values for the same key use a comma. E.g., “value1,value2”. All hosts are passed if no extra_specs are specified.ComputeFilter- passes all hosts that are operational and enabled.AggregateCoreFilter- DEPRECATED; filters hosts by CPU core number with per-aggregatecpu_allocation_ratiosetting. If no per-aggregate value is found, it will fall back to the global defaultcpu_allocation_ratio. If more than one value is found for a host (meaning the host is in two different aggregates with different ratio settings), the minimum value will be used.IsolatedHostsFilter- filter based onfilter_scheduler.isolated_images,filter_scheduler.isolated_hostsandfilter_scheduler.restrict_isolated_hosts_to_isolated_imagesflags.JsonFilter- allows simple JSON-based grammar for selecting hosts.AggregateRamFilter- DEPRECATED; filters hosts by RAM with per-aggregateram_allocation_ratiosetting. If no per-aggregate value is found, it will fall back to the global defaultram_allocation_ratio. If more than one value is found for a host (meaning the host is in two different aggregates with different ratio settings), the minimum value will be used.AggregateDiskFilter- DEPRECATED; filters hosts by disk allocation with per-aggregatedisk_allocation_ratiosetting. If no per-aggregate value is found, it will fall back to the global defaultdisk_allocation_ratio. If more than one value is found for a host (meaning the host is in two or more different aggregates with different ratio settings), the minimum value will be used.NumInstancesFilter- filters compute nodes by number of instances. Nodes with too many instances will be filtered. The host will be ignored by the scheduler if more thanfilter_scheduler.max_instances_per_hostalready exist on the host.AggregateNumInstancesFilter- filters hosts by number of instances with per-aggregatefilter_scheduler.max_instances_per_hostsetting. If no per-aggregate value is found, it will fall back to the global defaultfilter_scheduler.max_instances_per_host. If more than one value is found for a host (meaning the host is in two or more different aggregates with different max instances per host settings), the minimum value will be used.IoOpsFilter- filters hosts by concurrent I/O operations on it. hosts with too many concurrent I/O operations will be filtered.filter_scheduler.max_io_ops_per_hostsetting. Maximum number of I/O intensive instances allowed to run on this host, the host will be ignored by scheduler if more thanfilter_scheduler.max_io_ops_per_hostinstances such as build/resize/snapshot etc are running on it.AggregateIoOpsFilter- filters hosts by I/O operations with per-aggregatefilter_scheduler.max_io_ops_per_hostsetting. If no per-aggregate value is found, it will fall back to the global default :oslo.config:option:`filter_scheduler.max_io_ops_per_host. If more than one value is found for a host (meaning the host is in two or more different aggregates with different max io operations settings), the minimum value will be used.PciPassthroughFilter- Filter that schedules instances on a host if the host has devices to meet the device requests in the ‘extra_specs’ for the flavor.SimpleCIDRAffinityFilter- allows a new instance on a host within the same IP block.DifferentHostFilter- allows the instance on a different host from a set of instances.SameHostFilter- puts the instance on the same host as another instance in a set of instances.RetryFilter- DEPRECATED; filters hosts that have been attempted for scheduling. Only passes hosts that have not been previously attempted.AggregateTypeAffinityFilter- limits instance_type by aggregate.This filter passes hosts if no instance_type key is set or the instance_type aggregate metadata value contains the name of the instance_type requested. The value of the instance_type metadata entry is a string that may contain either a single instance_type name or a comma separated list of instance_type names. e.g. ‘m1.nano’ or “m1.nano,m1.small”
ServerGroupAntiAffinityFilter- This filter implements anti-affinity for a server group. First you must create a server group with a policy of ‘anti-affinity’ via the server groups API. Then, when you boot a new server, provide a scheduler hint of ‘group=<uuid>’ where <uuid> is the UUID of the server group you created. This will result in the server getting added to the group. When the server gets scheduled, anti-affinity will be enforced among all servers in that group.ServerGroupAffinityFilter- This filter works the same way as ServerGroupAntiAffinityFilter. The difference is that when you create the server group, you should specify a policy of ‘affinity’.AggregateMultiTenancyIsolation- isolate tenants in specific aggregates. To specify multiple tenants use a comma. Eg. “tenant1,tenant2”AggregateImagePropertiesIsolation- isolates hosts based on image properties and aggregate metadata. Use a comma to specify multiple values for the same property. The filter will then ensure at least one value matches.MetricsFilter- filters hosts based on metrics weight_setting. Only hosts with the available metrics are passed.NUMATopologyFilter- filters hosts based on the NUMA topology requested by the instance, if any.
Now we can focus on these standard filter classes in some detail. Some filters
such as AllHostsFilter and NumInstancesFilter are relatively simple and can be
understood from the code. For example, NumInstancesFilter has the following
implementation:
class NumInstancesFilter(filters.BaseHostFilter):
"""Filter out hosts with too many instances."""
def _get_max_instances_per_host(self, host_state, spec_obj):
return CONF.filter_scheduler.max_instances_per_host
def host_passes(self, host_state, spec_obj):
num_instances = host_state.num_instances
max_instances = self._get_max_instances_per_host(host_state, spec_obj)
passes = num_instances < max_instances
return passes
Here filter_scheduler.max_instances_per_host means the
maximum number of instances that can be on a host.
The AvailabilityZoneFilter looks at the availability zone of compute node
and availability zone from the properties of the request. Each compute service
has its own availability zone. So deployment engineers have an option to run
scheduler with availability zones support and can configure availability zones
on each compute host. This class’s method host_passes returns True if
availability zone mentioned in request is the same on the current compute host.
The ImagePropertiesFilter filters hosts based on the architecture,
hypervisor type and virtual machine mode specified in the
instance. For example, an instance might require a host that supports the ARM
architecture on a qemu compute host. The ImagePropertiesFilter will only
pass hosts that can satisfy this request. These instance
properties are populated from properties defined on the instance’s image.
E.g. an image can be decorated with these properties using
glance image-update img-uuid --property architecture=arm --property
hypervisor_type=qemu
Only hosts that satisfy these requirements will pass the
ImagePropertiesFilter.
ComputeCapabilitiesFilter checks if the host satisfies any extra_specs
specified on the instance type. The extra_specs can contain key/value pairs.
The key for the filter is either non-scope format (i.e. no : contained), or
scope format in capabilities scope (i.e. capabilities:xxx:yyy). One example
of capabilities scope is capabilities:cpu_info:features, which will match
host’s cpu features capabilities. The ComputeCapabilitiesFilter will only
pass hosts whose capabilities satisfy the requested specifications. All hosts
are passed if no extra_specs are specified.
ComputeFilter is quite simple and passes any host whose compute service is
enabled and operational.
Now we are going to IsolatedHostsFilter. There can be some special hosts
reserved for specific images. These hosts are called isolated. So the
images to run on the isolated hosts are also called isolated. The filter
checks if filter_scheduler.isolated_images flag named
in instance specifications is the same as the host specified in
filter_scheduler.isolated_hosts. Isolated
hosts can run non-isolated images if the flag
filter_scheduler.restrict_isolated_hosts_to_isolated_images
is set to false.
DifferentHostFilter - method host_passes returns True if the host to
place an instance on is different from all the hosts used by a set of instances.
SameHostFilter does the opposite to what DifferentHostFilter does.
host_passes returns True if the host we want to place an instance on is
one of the hosts used by a set of instances.
SimpleCIDRAffinityFilter looks at the subnet mask and investigates if
the network address of the current host is in the same sub network as it was
defined in the request.
JsonFilter - this filter provides the opportunity to write complicated
queries for the hosts capabilities filtering, based on simple JSON-like syntax.
There can be used the following operations for the host states properties:
=, <, >, in, <=, >=, that can be combined with the following
logical operations: not, or, and. For example, the following query can be
found in tests:
['and',
['>=', '$free_ram_mb', 1024],
['>=', '$free_disk_mb', 200 * 1024]
]
This query will filter all hosts with free RAM greater or equal than 1024 MB and at the same time with free disk space greater or equal than 200 GB.
Many filters use data from scheduler_hints, that is defined in the moment of
creation of the new server for the user. The only exception for this rule is
JsonFilter, that takes data from the schedulers HostState data structure
directly. Variable naming, such as the $free_ram_mb example above, should
be based on those attributes.
The RetryFilter filters hosts that have already been attempted for
scheduling. It only passes hosts that have not been previously attempted. If a
compute node is raising an exception when spawning an instance, then the
compute manager will reschedule it by adding the failing host to a retry
dictionary so that the RetryFilter will not accept it as a possible
destination. That means that if all of your compute nodes are failing, then the
RetryFilter will return 0 hosts and the scheduler will raise a NoValidHost
exception even if the problem is related to 1:N compute nodes. If you see that
case in the scheduler logs, then your problem is most likely related to a
compute problem and you should check the compute logs.
Note
The RetryFilter is deprecated since the 20.0.0 (Train) release
and will be removed in an upcoming release. Since the 17.0.0 (Queens)
release, the scheduler has provided alternate hosts for rescheduling
so the scheduler does not need to be called during a reschedule which
makes the RetryFilter useless. See the Return Alternate Hosts
spec for details.
The NUMATopologyFilter considers the NUMA topology that was specified for the instance
through the use of flavor extra_specs in combination with the image properties, as
described in detail in the related nova-spec document:
and try to match it with the topology exposed by the host, accounting for the
ram_allocation_ratio and
cpu_allocation_ratio for over-subscription. The filtering
is done in the following manner:
Filter will attempt to pack instance cells onto host cells.
It will consider the standard over-subscription limits for each host NUMA cell, and provide limits to the compute host accordingly (as mentioned above).
If instance has no topology defined, it will be considered for any host.
If instance has a topology defined, it will be considered only for NUMA capable hosts.
Configuring Filters¶
To use filters you specify two settings:
filter_scheduler.available_filters- Defines filter classes made available to the scheduler. This setting can be used multiple times.filter_scheduler.enabled_filters- Of the available filters, defines those that the scheduler uses by default.
The default values for these settings in nova.conf are:
--filter_scheduler.available_filters=nova.scheduler.filters.all_filters
--filter_scheduler.enabled_filters=ComputeFilter,AvailabilityZoneFilter,ComputeCapabilitiesFilter,ImagePropertiesFilter,ServerGroupAntiAffinityFilter,ServerGroupAffinityFilter
With this configuration, all filters in nova.scheduler.filters
would be available, and by default the ComputeFilter,
AvailabilityZoneFilter, ComputeCapabilitiesFilter,
ImagePropertiesFilter, ServerGroupAntiAffinityFilter,
and ServerGroupAffinityFilter would be used.
Each filter selects hosts in a different way and has different costs. The order
of filter_scheduler.enabled_filters affects scheduling
performance. The general suggestion is to filter out invalid hosts as soon as
possible to avoid unnecessary costs. We can sort
filter_scheduler.enabled_filters
items by their costs in reverse order. For example, ComputeFilter is better
before any resource calculating filters like NUMATopologyFilter.
In medium/large environments having AvailabilityZoneFilter before any capability or resource calculating filters can be useful.
Writing Your Own Filter¶
To create your own filter, you must inherit from BaseHostFilter and
implement one method: host_passes. This method should return True if a
host passes the filter and return False elsewhere. It takes two parameters:
the
HostStateobject allows to get attributes of the hostthe
RequestSpecobject describes the user request, including the flavor, the image and the scheduler hints
For further details about each of those objects and their corresponding attributes, refer to the codebase (at least by looking at the other filters code) or ask for help in the #openstack-nova IRC channel.
In addition, if your custom filter uses non-standard extra specs, you must
register validators for these extra specs. Examples of validators can be found
in the nova.api.validation.extra_specs module. These should be registered
via the nova.api.extra_spec_validator entrypoint.
The module containing your custom filter(s) must be packaged and available in the same environment(s) that the nova controllers, or specifically the nova-scheduler and nova-api services, are available in. As an example, consider the following sample package, which is the minimal structure for a standard, setuptools-based Python package:
acmefilter/
acmefilter/
__init__.py
validators.py
setup.py
Where __init__.py contains:
from oslo_log import log as logging
from nova.scheduler import filters
LOG = logging.getLogger(__name__)
class AcmeFilter(filters.BaseHostFilter):
def host_passes(self, host_state, spec_obj):
extra_spec = spec_obj.flavor.extra_specs.get('acme:foo')
LOG.info("Extra spec value was '%s'", extra_spec)
# do meaningful stuff here...
return True
validators.py contains:
from nova.api.validation.extra_specs import base
def register():
validators = [
base.ExtraSpecValidator(
name='acme:foo',
description='My custom extra spec.'
value={
'type': str,
'enum': [
'bar',
'baz',
],
},
),
]
return validators
setup.py contains:
from setuptools import setup
setup(
name='acmefilter',
version='0.1',
description='My custom filter',
packages=[
'acmefilter'
],
entry_points={
'nova.api.extra_spec_validators': [
'acme = acmefilter.validators',
],
},
)
To enable this, you would set the following in nova.conf:
[filter_scheduler]
available_filters = nova.scheduler.filters.all_filters
available_filters = acmefilter.AcmeFilter
enabled_filters = ComputeFilter,AcmeFilter
Note
You must add custom filters to the list of available filters using the
filter_scheduler.available_filters config option in
addition to enabling them via the
filter_scheduler.enabled_filters config option. The
default nova.scheduler.filters.all_filters value for the former only
includes the filters shipped with nova.
With these settings, nova will use the FilterScheduler for the scheduler
driver. All of the standard nova filters and the custom AcmeFilter filter
are available to the FilterScheduler, but just the ComputeFilter and
AcmeFilter will be used on each request.
Weights¶
Filter Scheduler uses the so-called weights during its work. A weigher is a way to select the best suitable host from a group of valid hosts by giving weights to all the hosts in the list.
In order to prioritize one weigher against another, all the weighers have to define a multiplier that will be applied before computing the weight for a node. All the weights are normalized beforehand so that the multiplier can be applied easily. Therefore the final weight for the object will be:
weight = w1_multiplier * norm(w1) + w2_multiplier * norm(w2) + ...
A weigher should be a subclass of weights.BaseHostWeigher and they can implement
both the weight_multiplier and _weight_object methods or just implement the
weight_objects method. weight_objects method is overridden only if you need
access to all objects in order to calculate weights, and it just return a list of weights,
and not modify the weight of the object directly, since final weights are normalized
and computed by weight.BaseWeightHandler.
The Filter Scheduler weighs hosts based on the config option filter_scheduler.weight_classes, this defaults to nova.scheduler.weights.all_weighers, which selects the following weighers:
RAMWeigherCompute weight based on available RAM on the compute node. Sort with the largest weight winning. If the multiplier,filter_scheduler.ram_weight_multiplier, is negative, the host with least RAM available will win (useful for stacking hosts, instead of spreading). Starting with the Stein release, if per-aggregate value with the keyram_weight_multiplieris found, this value would be chosen as the ram weight multiplier. Otherwise, it will fall back to thefilter_scheduler.ram_weight_multiplier. If more than one value is found for a host in aggregate metadata, the minimum value will be used.CPUWeigherCompute weight based on available vCPUs on the compute node. Sort with the largest weight winning. If the multiplier,filter_scheduler.cpu_weight_multiplier, is negative, the host with least CPUs available will win (useful for stacking hosts, instead of spreading). Starting with the Stein release, if per-aggregate value with the keycpu_weight_multiplieris found, this value would be chosen as the cpu weight multiplier. Otherwise, it will fall back to thefilter_scheduler.cpu_weight_multiplier. If more than one value is found for a host in aggregate metadata, the minimum value will be used.DiskWeigherHosts are weighted and sorted by free disk space with the largest weight winning. If the multiplier is negative, the host with less disk space available will win (useful for stacking hosts, instead of spreading). Starting with the Stein release, if per-aggregate value with the keydisk_weight_multiplieris found, this value would be chosen as the disk weight multiplier. Otherwise, it will fall back to thefilter_scheduler.disk_weight_multiplier. If more than one value is found for a host in aggregate metadata, the minimum value will be used.MetricsWeigherThis weigher can compute the weight based on the compute node host’s various metrics. The to-be weighed metrics and their weighing ratio are specified in the configuration file as the followings:metrics_weight_setting = name1=1.0, name2=-1.0
Starting with the Stein release, if per-aggregate value with the key metrics_weight_multiplier is found, this value would be chosen as the metrics weight multiplier. Otherwise, it will fall back to the
metrics.weight_multiplier. If more than one value is found for a host in aggregate metadata, the minimum value will be used.IoOpsWeigherThe weigher can compute the weight based on the compute node host’s workload. The default is to preferably choose light workload compute hosts. If the multiplier is positive, the weigher prefer choosing heavy workload compute hosts, the weighing has the opposite effect of the default. Starting with the Stein release, if per-aggregate value with the keyio_ops_weight_multiplieris found, this value would be chosen as the IO ops weight multiplier. Otherwise, it will fall back to thefilter_scheduler.io_ops_weight_multiplier. If more than one value is found for a host in aggregate metadata, the minimum value will be used.PCIWeigherCompute a weighting based on the number of PCI devices on the host and the number of PCI devices requested by the instance. For example, given three hosts - one with a single PCI device, one with many PCI devices, and one with no PCI devices - nova should prioritise these differently based on the demands of the instance. If the instance requests a single PCI device, then the first of the hosts should be preferred. Similarly, if the instance requests multiple PCI devices, then the second of these hosts would be preferred. Finally, if the instance does not request a PCI device, then the last of these hosts should be preferred.For this to be of any value, at least one of the
PciPassthroughFilterorNUMATopologyFilterfilters must be enabled.- Configuration Option
[filter_scheduler] pci_weight_multiplier. Only positive values are allowed for the multiplier as a negative value would force non-PCI instances away from non-PCI hosts, thus, causing future scheduling issues.
Starting with the Stein release, if per-aggregate value with the key
pci_weight_multiplieris found, this value would be chosen as the pci weight multiplier. Otherwise, it will fall back to thefilter_scheduler.pci_weight_multiplier. If more than one value is found for a host in aggregate metadata, the minimum value will be used.ServerGroupSoftAffinityWeigherThe weigher can compute the weight based on the number of instances that run on the same server group. The largest weight defines the preferred host for the new instance. For the multiplier only a positive value is allowed for the calculation. Starting with the Stein release, if per-aggregate value with the keysoft_affinity_weight_multiplieris found, this value would be chosen as the soft affinity weight multiplier. Otherwise, it will fall back to thefilter_scheduler.soft_affinity_weight_multiplier. If more than one value is found for a host in aggregate metadata, the minimum value will be used.ServerGroupSoftAntiAffinityWeigherThe weigher can compute the weight based on the number of instances that run on the same server group as a negative value. The largest weight defines the preferred host for the new instance. For the multiplier only a positive value is allowed for the calculation. Starting with the Stein release, if per-aggregate value with the keysoft_anti_affinity_weight_multiplieris found, this value would be chosen as the soft anti-affinity weight multiplier. Otherwise, it will fall back to thefilter_scheduler.soft_anti_affinity_weight_multiplier. If more than one value is found for a host in aggregate metadata, the minimum value will be used.BuildFailureWeigherWeigh hosts by the number of recent failed boot attempts. It considers the build failure counter and can negatively weigh hosts with recent failures. This avoids taking computes fully out of rotation. Starting with the Stein release, if per-aggregate value with the keybuild_failure_weight_multiplieris found, this value would be chosen as the build failure weight multiplier. Otherwise, it will fall back to thefilter_scheduler.build_failure_weight_multiplier. If more than one value is found for a host in aggregate metadata, the minimum value will be used.
CrossCellWeigherWeighs hosts based on which cell they are in. “Local” cells are preferred when moving an instance. Use configuration optionfilter_scheduler.cross_cell_move_weight_multiplierto control the weight. If per-aggregate value with the key cross_cell_move_weight_multiplier is found, this value would be chosen as the cross-cell move weight multiplier. Otherwise, it will fall back to thefilter_scheduler.cross_cell_move_weight_multiplier. If more than one value is found for a host in aggregate metadata, the minimum value will be used.
Filter Scheduler makes a local list of acceptable hosts by repeated filtering and weighing. Each time it chooses a host, it virtually consumes resources on it, so subsequent selections can adjust accordingly. It is useful if the customer asks for a large block of instances, because weight is computed for each instance requested.
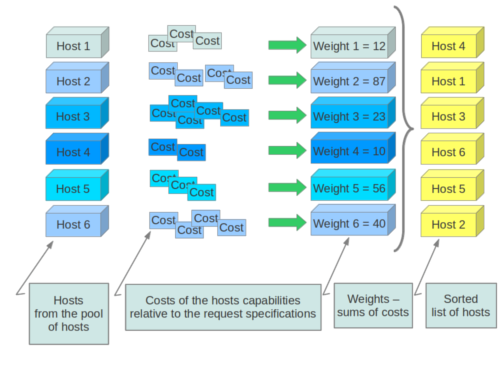
At the end Filter Scheduler sorts selected hosts by their weight and attempts to provision instances on the chosen hosts.
P.S.: you can find more examples of using Filter Scheduler and standard filters
in nova.tests.scheduler.
