Understanding Magnum Cluster API Helm Driver¶
Introduction¶
Since moving away from using Heat in order to provision Kubernetes clusters, Magnum, like many other projects, has transitioned to Cluster API (CAPI) for managing these clusters.
As an active Kubernetes project, Cluster API uses software extensions, called operators, to provide a declarative API for cluster lifecycle management.
Magnum occupies a unique and important role in the OpenStack ecosystem as the project that acts as a bridge between OpenStack and Kubernetes’ Cluster API (CAPI); acting to further expand OpenStack’s capabilities. Effectively, this provides users the ability to create Kubernetes clusters using the OpenStack API, bypassing the need to directly interact with Kubernetes or its API.
Therefore this document, based on the following blog post , aims to provide a comprehensive guide to the Magnum Cluster API Helm Driver to aid in understanding its implementation and architecture.
Note
The Magnum Cluster API Helm Driver is reliant on the pre-installation of some OpenStack services on the target cloud before being able to be deployed. This list includes all the core OpenStack components - Keystone, Glance, Neutron, Cinder & Nova - as well as Octavia (API load balancers), Barbican (cluster certificates) and Magnum itself.
Core CAPI Concepts¶
As previously defined, Cluster API provides an API for being able to manage the various components of a Kubernetes cluster. This conceptually looks like a Kubernetes cluster managing other Kubernetes clusters; the former, named the ‘CAPI management cluster’, is the one providing the API for managing the latter workload clusters.
The CAPI management cluster provides this API via a set of custom resource
definitions (CRDs).
These CRDs are groupings of API objects which, in turn, together make up the
Kubernetes cluster; for example, the pods resource is an endpoint in the
Kubernetes API containing, specifically, pod related objects which are
targeted when performing operations on pods. However, pods is a built-in
resource in Kubernetes, whereas CRDs are, as the name implies, custom and
contain a select set of objects depending on the CRD’s purpose.
One could manually target these CRDs to deploy a Kubernetes application and then manage it, but this isn’t very efficient or scalable. This is where Kubernetes operators come in. Also known as controllers, these operators are a way of packaging, deploying and managing a Kubernetes application in an automated way. Furthermore, Kubernetes operators keep an eye on the CRDs and, when a change is detected, they will take the necessary actions to ensure these changes are reflected in the cluster.
Therefore, the Magnum Cluster API management cluster consists of a collection of CRDs set into motion and monitored by a set of operators. The diagram below highlights these various components and their relationships:

Note
[1]: The addons.stackhpc.com API group will be renamed in the future, as more of the relevant
source code repositories are donated by StackHPC to be under the control of an open-governance foundation.
Note
Here are the generalised roles of the various CRDs from the diagram above:
clusters.cluster.x-k8s.io
The top-level resource representing a single workload cluster.
machinedeployment.cluster.x-k8s.io
The
Machineequivalent of a Kubernetes pod Deployment which manages a set of pods for the purpose of running an application workload.
machine.cluster.x-k8s.io
A representation of an individual machine, usually a VM, belonging to a workload cluster.
kubeadmconfigtemplate.cluster.x-k8s.io & kubeadmcontrolplane.cluster.x-k8s.io
Kubeadm is a tool for bootstrapping standard Linux hosts and converting them into Kubernetes cluster nodes. Combined with the relevant controllers, these two CRDs provide a declarative interface for node bootstrapping and configuration.
openstack{cluster,machinetemplate,machine}.infrastructure.cluster.x-k8s.io
A representation of the OpenStack cloud resources required by a single workload cluster. The cluster-api-provider-openstack (
capo-controller-managerin the above diagram) is responsible for reconciling the state of these resources using OpenStack API calls. Thecluster-api-janitoralso watches these CRDs to clean up any OpenStack resources left behind upon deletion of the workload cluster.
{helmrelease, manifests}.addons.stackhpc.com & helmchartproxy.addons.cluster.x-k8s.io
A representation of a Helm release or plain Kubernetes manifest to be installed on a workload cluster. Installation and subsequent reconciliation are carried out by the cluster-api-addon-provider.
Note
To view a list of the installed CRDs on a given Kubernetes cluster, run kubectl get crds.
Making Workload Clusters Reproducible¶
The benefits in making cluster deployments as reproducible and consistent as possible are well known; so how is this achieved in the context of the Magnum Cluster API? The Magnum CAPI Helm driver uses images, often built and tested by CI pipelines, which are then referenced in a Magnum cluster template in order for them to then be targeted.
Nevertheless, the way in which these images are used and managed can vary, each appropriate for different use cases. For example, the following section of the driver development environment script utilises OpenStack CLI to download, then upload the latest stable image to the target cloud, followed by generating a corresponding cluster template; which is more suited to a development environment. Whereas, a more production-ready approach would involve a level of version control for both the images and the cluster templates. An example of which can be found in the following Ansible playbook.
High availability CAPI Management Clusters¶
A typical requirement for a production environment is for the CAPI management cluster to be highly available, which by default, the Magnum CAPI Helm driver’s deployment isn’t. However, by utilising the following Ansible tooling, alongside this specific example configuration, it is possible to deploy a high availability CAPI management clusters.
The resulting Magnum CAPI management cluster architecture will result in a highly-available, auto-healing Kubernetes cluster which itself is managed by a Cinder-backed lightweight k3s cluster. The illustration below provides a visual representation of this architecture:
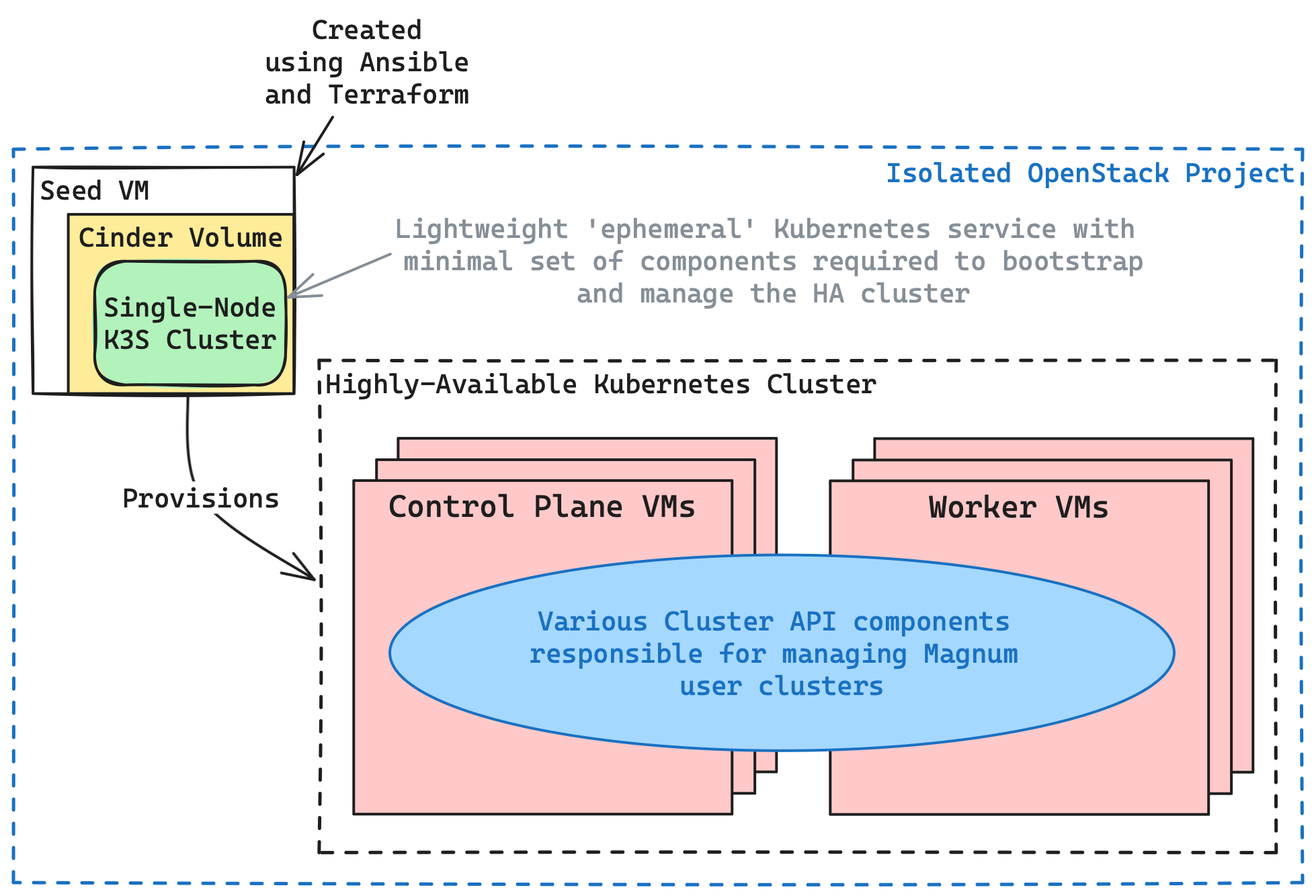
Some of the key features of the Ansible tooling’s resulting architecture include:
Version-controlled:
-
Simplify routine maintenance and updates.
-
Using regularly upstream CI tested processes.
Remote Terraform state storage
For the purpose of maintaining the state of the Seed VM.
